My home lab has been running with primary storage provided via an all-flash implementation of VMware vSAN for almost 4 years now.
The underlying drives are consumer-grade Samsung 850 EVO 120gb (cache) and 500gb (capacity) SSD drives. Six months ago, vSAN started showing health warnings for the cache drive on one of the ESXi hosts which a few months later finally resulted in the vSAN disk group for that host being marked offline.
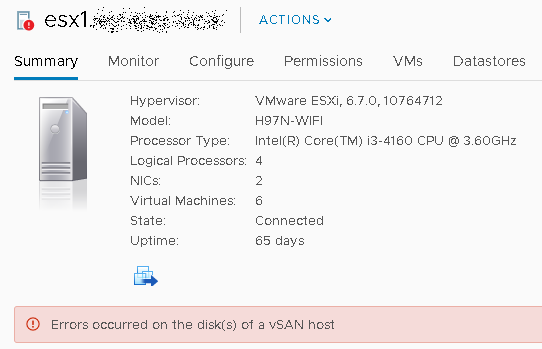
This wasn’t a totally unexpected event, although I was surprised in how long the SSD drives had lasted for. I ordered some cheap Gigabyte 120gb replacement SSD’s for all hosts, assuming that the other cache drives would likely die soon as well and thought it worthwhile to note down the process I used to replace the failed cache SSD and get the vSAN disk group back up and running.
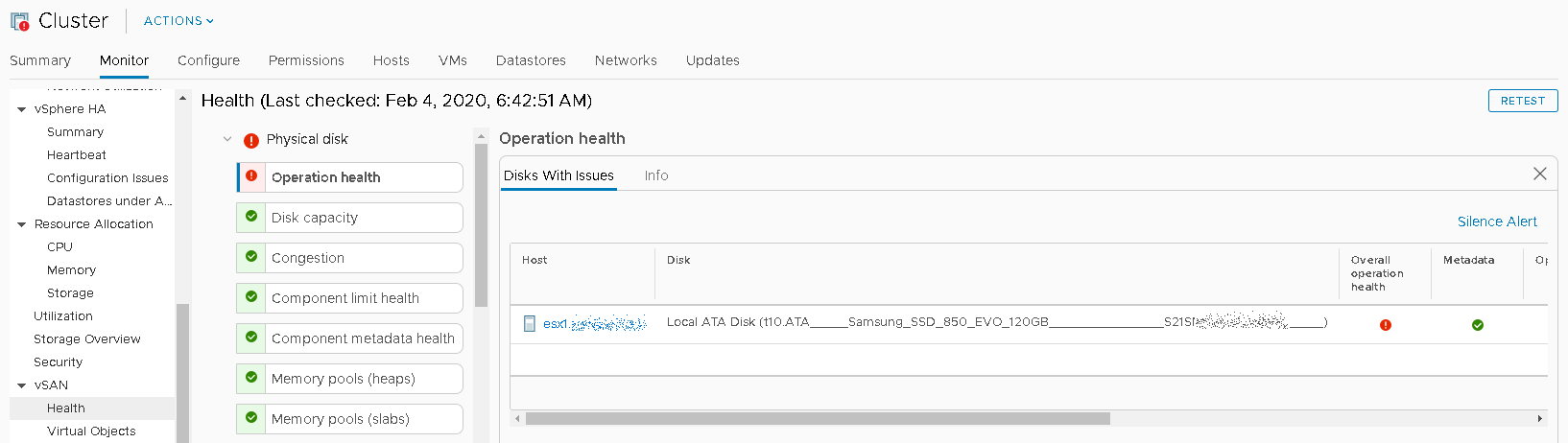
First, I went to Cluster-> Monitor-> vSAN-> Health, and expanded the Physical disk section to confirm it was the 120gb cache drive that needed to be replaced on the host.
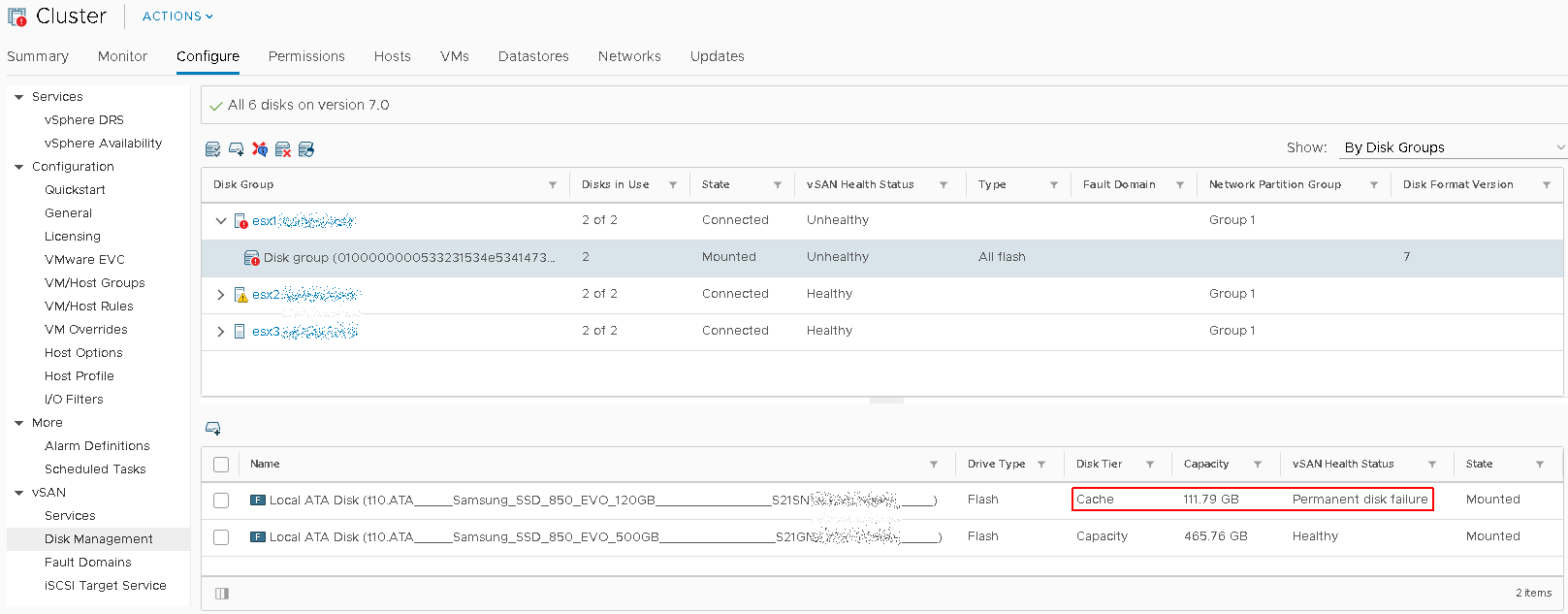
Then I went to Cluster-> Configure-> vSAN-> Disk Management, and expanded the Disk Group for the host ESX1 which shows the cache drive was showing Permanent disk failure
I then clicked the icon to Remove the disk group and was given options around vSAN data migration. While the drop-down does let me select “Full data migration”, this option would have resulted in failure since the disk group is unavailable. Instead, I selected “No data migration” and was given the warning that objects would become non-compliant with my vSAN storage policy.
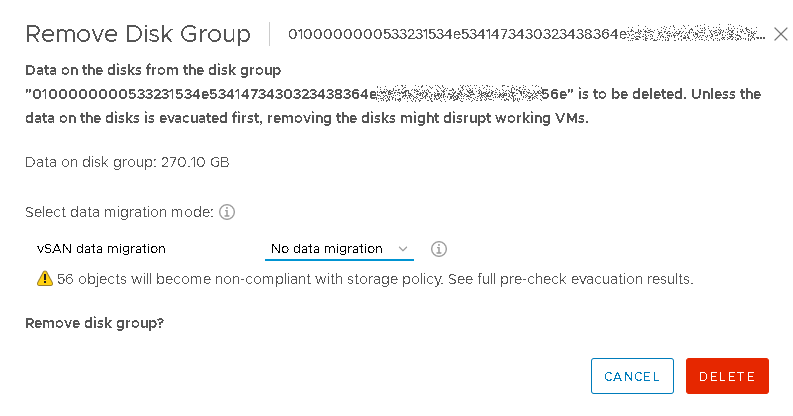
Selecting “Delete”, I could then see the progress in the Recent Tasks bar

Once the task completed, I then put the host into maintenance mode, powered off the host, replaced the dead Samsung SSD with a new Gigabyte SSD and powered the host back on. Once the host was back up, I again went into Cluster-> Configure-> vSAN-> Disk Management, selected the host ESX1 and then clicked on the “Claim Unused Disks for vSAN” icon. This let me select the new Gigabyte 120gb SSD for the cache tier and the remaining Samsung 500gb SSD for the capacity tier.
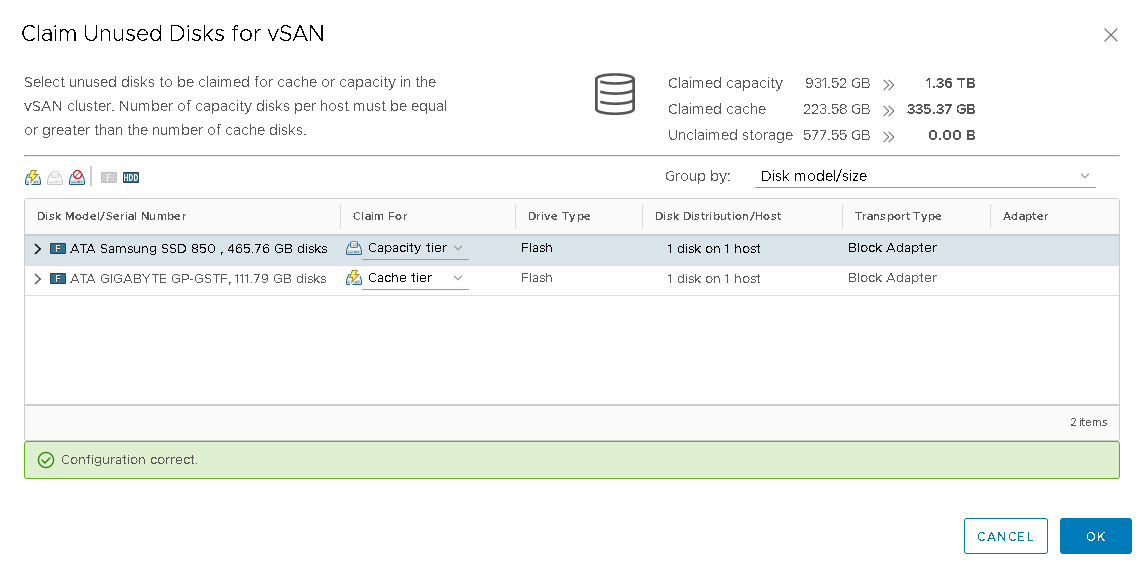
After clicking “OK”, a new vSAN disk group was created and the SSD’s were added to it.
Once the vSAN disk group is created, data needs to be synced to it based on your VM Storage Policies. The progress of this sync can be checked on by going into Cluster-> Monitor-> vSAN-> Resyncing Objects. This will show you how many objects need to be resynced, and the amount of data and time left to go for each object. Most of the time the resync operation starts immediately, but it is worth remembering that vSAN has a 60-minute default window before it performs any remediation actions due to a failure. My home lab started its resync operation immediately due to exceeding this 60-minute window but if your environment has not, then you may need to click the “Resync Now” button.

It is also worth pointing out the button for “Resync Throttling” in the top-right. Be default the sync rate is set to 512Mbps which is suitable for a 10Gbps LAN, but if you have a slow vSAN network link (perhaps from using a 1Gbps switch like my lab does) and/or heavily utilised hosts with multiple disk groups, then you may run into issues during the sync process. By enabling the Resync Throttling option you can limit the bandwidth used to anything between 1Mbps and 512Mbps which can let your hosts keep up with normal VM and User traffic while taking slightly longer to resync the vSAN objects. You can also see the current traffic utilisation of your hosts in this window.

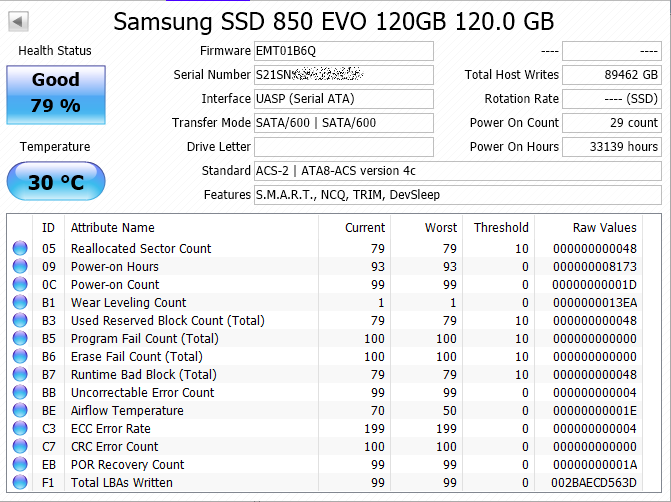
While my hosts completed their resync, I put the failed Samsung 120gb SSD into an external USB3 enclosure and ran CrystalDiskInfo so I could check the SMART statistics on the failed SSD. After 33,139 (3.8 years) of Power On Hours, and almost 90Tb of writes, I figured the Samsung had done pretty well for a drive only rated for 75Tb Total Bytes Written!